1.什么是大模型?
大模型又可以称为Foundation Model(基石)模型,模型通过亿级的语料或者图像进行知识抽取,学习进而生产了亿级参数的大模型。其实感觉就是自监督学习,利用大量无标签很便宜的数据去做预训练。
比如BERT,怎么做的无监督pre-trained?他会把输入的句子中的token随机遮住,然后去预测这个token经过encoder以后的输出单词的概率(通过softmax),因为我们自己是知道哪个token被遮住了的,loss就是让模型预测的记过越来越接近真实值(有一个词汇表,可以编码GT的one-hot),通过这样来反传播训练。
2.大模型能解决什么问题?
大规模预训练可以有效地从大量标记和未标记的数据中捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,极大地扩展了模型的泛化能力。在应对不同场景时,不再从0开始,只需要少量的样本进行微调
再比如BERT已经训练好了,我们要做下游任务,做一个句子的情感分析。那么就会在BERT的输入token中加入一个 class token,这个和vit的做法一样,encoder以后用class token的向量做一下linear transoformation 和softmax和gt做损失训练,所以这一步可以直接初始化BERT模型的预训练参数做finetune,效果要更好。收敛的又快,loss又低。
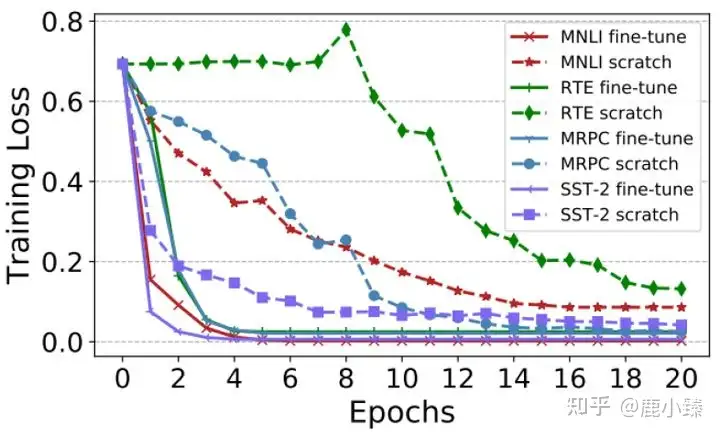
预训练模型的初始化结果
3.大模型怎樣finetune
比如MAE在訓練的時候,Encoder部分是(大的Vit結構),decoder部分是(小的vit結構),pretraind的時候
都訓,在做imagenet分類任務的時候,保留encoder部分,加上分類頭,進行finetune就可以啦(可以部分網絡+分類器訓練)。
讲的很赞。
科技猛兽:Self-Supervised Learning 超详细解读 (三):BEiT:视觉BERT预训练模型
科技猛兽:Self-Supervised Learning 超详细解读 (六):MAE:通向 CV 大模型
开源pretrain模型
科技猛兽:Self-Supervised Learning 超详细解读 (七):大规模预训练 Image BERT 模型:iBOT
4.大模型实际应用
MAE (不算是大模型了) 最大才600+M的参数,自己在IN1K(128万数据)上自监督训练,然后在finetune,得到的一些结果。
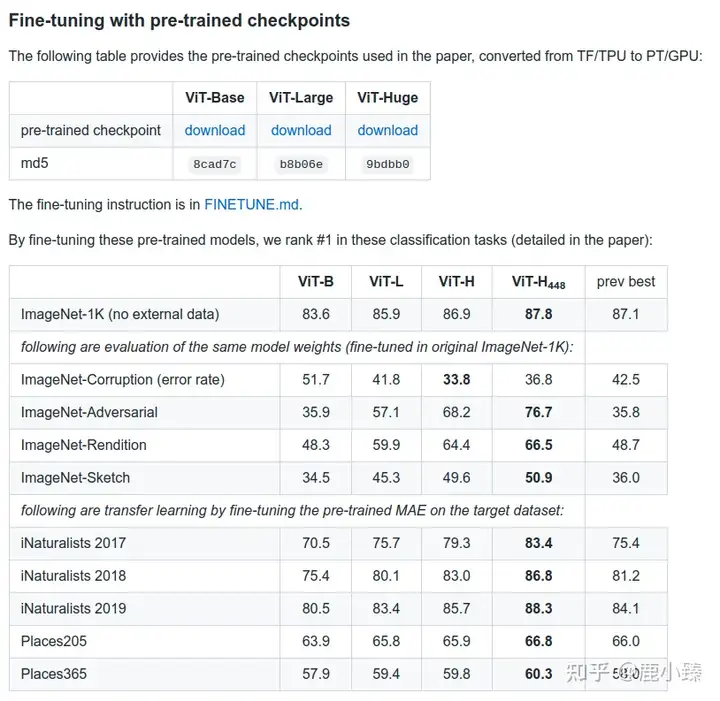
MAE 一些结果
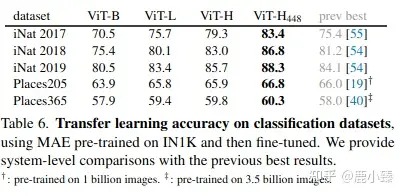
MAE在下游任务结果

自监督模型参数量

自监督模型参数量
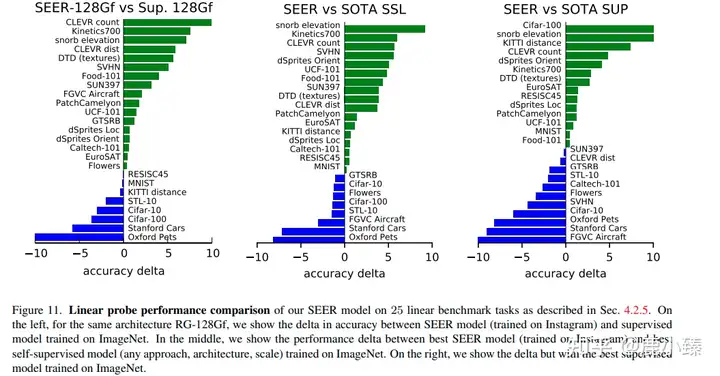
SEER在Imagenet上看到的可以称之为小小大模型的模型。(其实论文里说用了大概10M的图片,但是保证了分布,比如跨国家,跨性别)
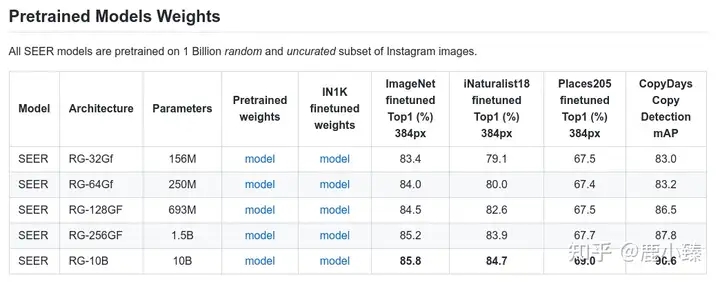
SEER的一些结果
单论Imagenet好像输了。其他下游任务好像赢了,比如Places205,但是赢的代价也太大了.
想用大模型就要下游任务依赖它的结构,目前看到的都是完全复制它的结构初始化参数finetune,真正大模型对于显存有要求。